

Bei der Analyse einer großen Anzahl von Textdatensätzen ist es unmöglich händisch
alle Themen der Texte zu Klassifizieren und Bezüge der einzelnen Text herzustellen. Die dazu benötigten Kategorien können durch Clusterung gefunden werden und bestehende manuell erstellte Kategorien ergänzen.
Scikit-Learn, eine Python Library für Machine Learning Funktionen, bietet einige Möglichkeiten, um die Aufgaben des Topic Modellings und der Clusterung abzubilden.
Zusätzlich dazu bietet die Library auch Preprocessing-Funktionen und Manipulationsmethoden zur Bereinigung.
Topics und Cluster
Topics können als Themen verstanden werden, zum Beispiel wenn man an Support Tickets
denkt, die Ticket-Kategorien und Prioritäten, welche den Support Tickets zugewiesen werden. Oft liegen historische Daten nur in wenigen bereits vorher definierten Kategorien vor, beziehungsweise existiert auch meistens eine große Anzahl von Datensätzen ohne jegliche Kategorie. Diese wären für das Training des Modells unbrauchbar, können jedoch analysiert werden, um noch unerkannte Kategorien zu erkennen (Topic Modelling) und auch um thematisch ähnliche Support Tickets in Clustern zu gruppieren.
Die Ergebnisse einer solchen Clusterung können später bei der grafischen Präsentation des Outputs – also den durch Clusterung erweiterten Kategorien an den Support Ticktes (welche ML-unterstützt kategorisiert werdne können danach) auch dazu führen eine Recommender Funktion für das Supportpersonal anbieten zu können, bzw. schnell Support Tickets mit ähnlichen Topics vorschlagen und visualisieren zu können, um die Lösungssuche zu beschleunigen. Somit gibt es verschiedene gute Gründe warum RAW-Daten zusätzlich zur Kategorisierung (Supervised Learning) zum beispiel vorher auch einem Topic Modelling und der Clusterung unterzogen werden.
Um bei dem gewählten Beispiel von Support Tickets zu bleiben: Topics können als die Themen (Kategorien) der der Support-Tickets verstanden werden, und die Cluster sind dementsprechend eine Darstellung von Topics mit ähnlichen Attributen. [1]
TF-IDF Topic Modelling
TF-IDF steht für Term Frequency (TF) – Inverse Document Frequency (IDF) und versucht die „Wichtigkeit“ eines Terms (eines Wortes zum Beispiel) in einem Dokument zu bestimmen, wenn man Dieses mit der Gesamtmenge der zu analysierenden Dokumente vergleicht. TF-IDF gehört zu den regelbasierten Methoden der Textanalyse. Zum Beispiel ist diese Funktion von Suchmaschinen bekannt, aber auch beim Durchsuchen der Textinformation der vorliegenden Jira Tickets anwendbar. Eine Suche nach dem Begriff „Drucker“ durchforstet eine Gesamtmenge an Dokumenten nach dem Term und jene, wo die Verwendung dieses Begriffs am relevantesten ist, werden der suchenden Person als erstes Suchergebnis angezeigt. Formel 1 zeigt die Berechnung
des TF-IDF Wertes des Terms:
TF-IDF Wert = TF * IDF
Formel 1: Berechnung des TF-IDF Gewichts eines Terms
Der Term Frequency (TF) Wert zählt, wie oft ein Wort (nVORK) in einem Dokument mit
einer Anzahl von Worten (nWORTE) vorkommt. Somit ist es der Quotient aus der Anzahl
der Vorkommnisse dividiert durch die Gesamtanzahl der Worte im Dokument, wie
Formel 2 veranschaulicht.
TF = nVORK / nWORTE
Formel 2: Term Frequency (TF) Berechnung
Der Inverse Document Frequency Wert (IDF) sieht sich die Häufigkeit des Terms in allen
betrachteten Dokumenten an, zum Beispiel wie viele Dokumenten beinhalten den Begriff
„Drucker“, um beim oben gewählten Beispiel zu bleiben, überhaupt. Hierbei bildet man
erst den Quotienten aus der Gesamtanzahl (nGES) der zu betrachtenden Dokumente und
der Anzahl der Dokumente n(DOK) welche den Term beinhalten, und logarithmiert diesen
Quotienten anschließend, hier gezeigt in Formel 3.
IDF = log(nGES / nDOK)
Formel 3: Inverse Document Frequency (IDF) Berechnung
[2]
Die Verwendung von Scikit-Learn ist hier eine große Hilfe, da die Berechnung der
Einzelwerte für TF und IDF, sowie deren Produkt vollautomatisiert für die Gesamtheit
der zu analysierenden Dokumente durchgeführt wird. Als nächster Schritt zum Clustering wird hier die Methode K-Means eingesetzt. Dies bezeichnet eine ML-Clustering-Methode aus dem Bereich des unüberwachten Lernens, bei welcher jedes untersuchte Dokument anhand seiner Topics und jenen seiner nächstgelegenen Nachbarn (in Bezug auf Wertigkeit) gruppiert wird. Das K steht für die Anzahl von zu bildenden Clustern und alle Dokumente werden nun diesen Clustern, anhand definierter Eigenschaften (zum Beispiel des TF-IDF Wertes der Kategorien) einem dieser Cluster zugeordnet. Danach werden die Cluster aktualisiert, um die neuen Daten zu repräsentieren. Scikit-Learn bietet ebenfalls alle nötigen Algorithmen, um dieses Clustering durchzuführen.
Mithilfe der Kombination aus TF-IDF und K-Means Clustering kann jedoch jedem der
Dokumente nur genau ein Topic, also nur genau eine Kategorie zugewiesen werden.
Man könnte also ein Support Ticket als Druckerproblem kategorisieren, jedoch könnte
keine zweite Kategorie, wie die Priorität als Beispiel, dargestellt werden. Es müssen die
einzelnen Dokumente in den Clustern in einem zweiten Durchgang prozessiert werden,
um die Clusterung nach der Priorität innerhalb des Clusters „Drucker“, als Beispiel,
durchzuführen. Ebenfalls können damit nicht, oder nur mit erhöhtem Aufwand, multiple
Topics eines Tickets dargestellt werden. Als Beispiel kann ein Support Ticket das Topic
„Drucker“ haben, ebenso das Topic „Bestellung“ – da ein neuer Drucker gekauft werden
soll und wäre somit für die Einkaufsabteilung relevant. Ein weiteres Support Ticket
beschäftigt sich ebenfalls mit Druckern, hat also „Drucker“ als Topic zugewiesen
bekommen, erfordert aber ein Eingreifen der IT-Abteilung, da ein Toner getauscht
werden muss – das korrespondierende Topic könnte als „Hardware Fehler“ sein. KMeans ist also nur bedingt geeignet, nämlich für ein initiales Clustering in Haupttopics,
würde doch bei der Multidimensionalität komplexer Texte, wie jener unsere Support
Tickets, an seine Grenzen stoßen. TF-IDF Topic Modelling und das Clustering via KMeans gibt jedoch bereits einen groben Überblick der Hauptkategorie eines Support
Tickets und erlaubt eine Abschätzung, wie relevant die vorhandenen Kategorien sind.
Die Methode ist jedoch als alleiniges Werkzeug zur Kategorisierung von Daten manchmal nicht geeignet.
Latent Dirichlet Allocation (LDA) Topic Modelling
Als oft besser geeignete Topic Modelling / Clustering Methode wird die „Latent Dirichlet
Allocation (LDA) erachtet. Hierbei handelt es sich um eine ML-Methode (ebenfalls
unbeaufsichtigtes Lernen), welche in der Lage ist, die betrachteten Dokumente nicht nur
einem einzigen Topic-Cluster, wie beim K-Means Clustering, sondern mehreren Clustern
gleichzeitig zuzuordnen, je nach Übereinstimmung der gefundenen Topics. Sie basiert
auf dem gleichnamigen probabilistischen Modell, also einem mathematischen Modell,
welches sich mit Zufallsvariablen und Wahrscheinlichkeitsverteilungen beschäftigt,
welches von Blei, Ng und Jordan im Jahr 2003 in ihrem Paper „Latent Dirichlet
Allocation“ vorgestellt wurde. [3]
Die Abbildung 1 veranschaulicht, sehr vereinfacht, den Prozess der Clusterbildung für
das vorherige Beispiel von Support Tickets mit den Topics „Drucker“, „Einkauf“, „Toner“
und erweitert dieses Beispiel noch um die Dimension der „Priorität“.
LDA Topic Modelling in Python mit der Gensim Library gut implementiert und lässt sich
bequem in Jupyter Notebooks aufrufen und visualisieren. Das korrekte Preprocessing,
die Bereinigung und Feature Engineering sind jedoch wichtige Voraussetzungen für
diese Methode, auf welche im Methodik Teil dieser Arbeit detaillierter eingegangen wird.
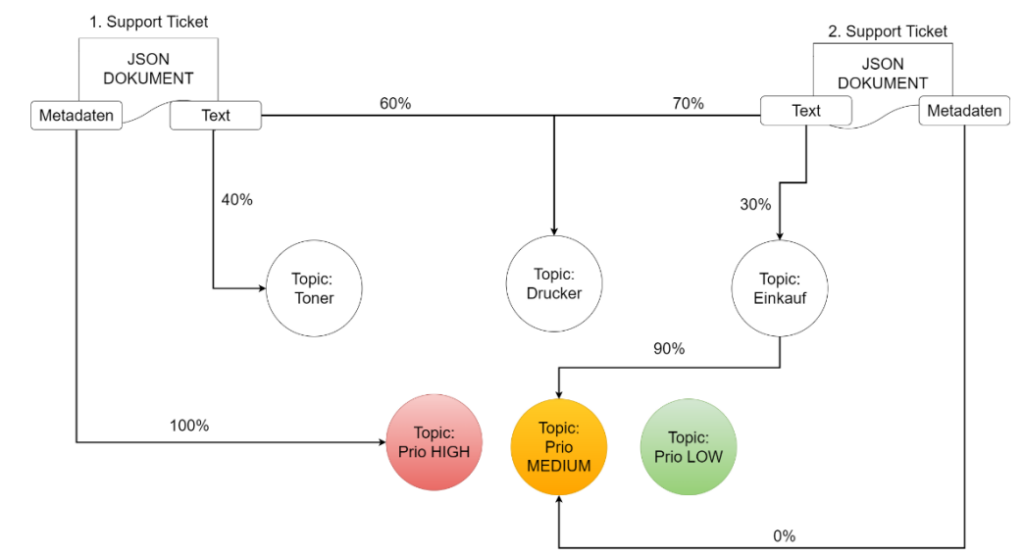
Abbildung 1: LDA Topic Modelling – Cluster Zuweisung
Beispiel JSON Dokument 1: In Abbildung 2 wird das JSON-Dokument 1, welches
Textinformation und Metadaten enthält, mittels LDA analysiert und den jeweiligen
Clustern der Topics zugewiesen. Hier im Beispiel der Grafik sehen wir das die
Textinformation von Dokument 1 zu 60% dem Topic „Drucker“ zugeordnet und zu 40%
dem Topic „Toner“. Es bleiben 0% für das Topic „Einkauf“, somit kann die Aussage
getätigt werden, dass es sich um eine Support Anfrage handelt, die sich mit dem Drucker
und spezifisch dem Toner beschäftigt. Beide Kategorien können somit in der JSON-Datei
eingetragen werden.
Weiters hat die Datei in den Metadaten die Ticket Priorität übergeben bekommen, da
diese im Ticket richtig eingetragen war. Die Priorität entspricht hier also zu 100% „HIGH“
und wird als weitere Kategorie in die JSON-Datei übernommen, um später das
korrespondierende Jira Support Ticket über die API mit den ML-bestimmten
Informationen zu aktualisieren.
Beispiel JSON Dokument 2: Das zweite Dokument in der Abbildung 1 kann anhand
des Textinhaltes ebenfalls zu 70% dem Topic „Drucker“ zugehörig erkannt werden, und
der restliche Inhalt des Textes deutet zu 30% darauf hin, dass es sich dabei um eine
Anfrage zur Bestellung eines neuen Druckers handelt, somit um das Topic „Einkauf“.
Wieder bleiben 0% für das Topic „Toner“, es handelt sich also nicht um eine Support
Anfrage für den Toner.
Jedoch wurde hier in den Metadaten keine Priorität mit übergeben. Somit kann die
Priorität „MEDIUM“ nicht über die Metadaten ermittelt werden, wie in Beispiel 1. Jedoch
haben 90% des Topic Clusters „Einkauf“ die Priorität „MEDIUM“ und somit wird das JSON-Dokument mit den Kategorien „Drucker“, „Einkauf“ und „MEDIUM“ als Priorität
aktualisiert.
Bibliographie
Text dieses Artikels ist ein angepasster Auszug aus “B.Schön, Komparative Analyse von Machine-Learning Methoden zur Klassifizierung und Priorisierung von Support Tickets der Firma Springtime Technologies GmbH, Feb. 2024, Bachelorarbeit”
Originalreferenzzahlen Arbeit: [19], [20], [21]
Artikelreferenzen
[1] G. W. Milligan und M. C. Cooper, „Methodology Review: Clustering Methods“, Appl. Psychol. Meas., Bd. 11, Nr. 4,
S. 329–354, Dez. 1987, doi: 10.1177/014662168701100401.
[2] J. Ramos, „Using TF-IDF to Determine Word Relevance in Document Queries“
[3] D. M. Blei, „Latent Dirichlet Allocation“, S. 30.