

Multiclass Decision Forests basieren auf Decision Trees, also Entscheidungsbäumen, jedoch ohne Abstriche in Bezug auf Flexibilität in Kauf nehmen zu müssen. Decision Forests bieten die gleiche Einfachheit wie auch Entscheidungsbäume, jedoch durch die Kombinationsmöglichkeiten steigert sich deren Genauigkeit enorm gegenüber einzelnen Entscheidungsbäumen, welche sehr gut an den initialen Trainingsdaten angewendet werden können, jedoch Schwächen zeigen, wenn es um die Voraussage bzw. Kategorisierung von neuen Daten geht.
Multiclass Decision Forests basieren auf Decision Trees, also Entscheidungsbäumen, jedoch ohne Abstriche in Bezug auf Flexibilität in Kauf nehmen zu müssen. Decision Forests bieten die gleiche Einfachheit wie auch Entscheidungsbäume, jedoch durch die Kombinationsmöglichkeiten steigert sich deren Genauigkeit enorm gegenüber einzelnen Entscheidungsbäumen, welche sehr gut an den initialen Trainingsdaten angewendet werden können, jedoch Schwächen zeigen, wenn es um die Voraussage bzw. Kategorisierung von neuen Daten geht.
Die generelle Vorgehensweise hier ist, dass ein „Bootstrapped“ Sample erstellt wird, also mit randomisierten Teilmengen der Daten versehen wird, und daraus ein Entscheidungsbaum gefertigt wird. Dieser Vorgang wird sehr oft wiederholt, bis sich ein „Wald“ aus vielen einzelnen Entscheidungsbäumen bildet, welche alle unterschiedlich sind, jedoch alle auf den Bootstrap-Datensätzen basieren. Genau diese Unterschiede der einzelnen Bäume lässt diese Methode flexibel mit neuen Trainingsdaten umgehen. [1]
Neue Datensätze (nicht kategorisierte JSON-Dateien) sollen, um bei dem bereits gewählten Beispiel zu bleiben, kategorisiert werden als Druckerproblem. Dabei wird die Anzahl der Worte im Dokument gemessen und mit Schwellwerten verglichen. Tabelle 1 zeigt eine solche fiktive Zählung der Wörter in Dokumenten:
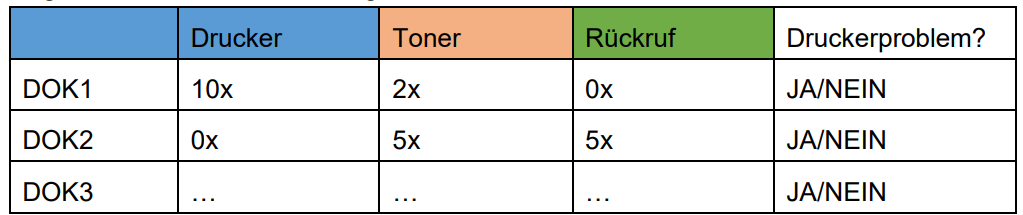
Tabelle 1: fiktive Wortzählung zur Kategorisierung
Nun muss entschieden werden welche der Variablen, hier also Wörter, zur Kategorisierung der Wurzel des Baumes herangezogen wird, zum Beispiel „Drucker“, und damit wird der erste Entscheidungsbaum gebildet. Dabei gilt zu beachten, dass aus den Variablen der Tabelle oben nur eine Anzahl randomisierter Werte verwendet werden, es können auch Werte doppelt verwendet werden. Kommen neue Datensätze nun in den Random Forest, dann werden sie durch alle enthaltenen Entscheidungsbäume geschickt und je nach Konfiguration der einzelnen Bäume kann hier eine Klassifizierung am Ende erzielt werden. Dabei kann es sein, dass ein Baum das Problem als Druckerproblem klassifiziert, anhand der Werte für die einzelnen Worte, ein anderer jedoch das Problem nicht als Druckerproblem klassifiziert.
Diese Entscheidungen werden nun aggregiert und nach Durchlauf des gesamten Forests gibt es eine Mehrheit für die Entscheidung zur Klassifizierung des Problems. Die zwei beschriebenen Vorgänge, Bootstrapping und Aggregatbildung, werden als „Bagging“ bezeichnet. Jene Datensätze, welche nicht in im Bootstrap-Sample zur Bildung des Decision Forests inkludiert wurden, werden als Out-of-Bag Sample bezeichnet und sind ein Indikator für die Genauigkeit des gebildeten Forests. Diese Datensätze sollten nun nämlich richtig klassifiziert werden. Die Ergebnisse werden als Feedback zur Verfeinerung der Variablen (Variable-Tuning) genutzt, um die beste Anzahl an Startvariablen zu finden, um die größtmögliche Genauigkeit des Decision Forests zu garantieren.
Scikit-Learn hat auch hier wieder alle Tools zur Hand, um die vorliegenden Trainingsdaten anhand der vorher gewählten Kategorien zu klassifizieren. Python verwendet dabei die Gini-Impurity und Entropiewerte, um die Trennungspunkte (Splits) zu entscheiden und die Bäume zu kreieren. [2]
Auch wenn in Decision Forests numerische Daten mit Boolean Werten zum Beispiel gemischt werden können, beschränkt sich diese Arbeit auf die Messungen der Anzahl der Vorkommen der Worte um die Kategorien als Wurzelelement bestimmen zu können. Anhand definierter Parameter kann eine korrekte Klassifizierung, bzw. auch multiple Klassifizierungen bei Texten mit gemischtem Inhalt, erwartet werden. Da die Texte der
Support Tickets einen thematisch Ähnlichen Inhalt aufweisen, kann ein gut getunter MDF-Algorithmus eine große Genauigkeit der Klassifizierung erreichen.
Bibliographie
Text dieses Artikels ist ein angepasster Auszug aus “B.Schön, Komparative Analyse von Machine-Learning Methoden zur Klassifizierung und Priorisierung von Support Tickets der Firma Springtime Technologies GmbH, Feb. 2024, Bachelorarbeit”
Originalreferenzzahlen Arbeit: [35], [36]
Artikelreferenzen
[1] A. Das, „Decision Tree Algorithm for Multiclass problems using Python“, Medium. Zugegriffen: 29. Dezember 2022.
[Online]. Verfügbar unter: https://towardsdatascience.com/decision-tree-algorithm-for-multiclass-problems-usingpython-6b0ec1183bf5
[2] „1.12. Multiclass and multioutput algorithms“, scikit-learn. Zugegriffen: 4. Januar 2023. [Online]. Verfügbar unter:
https://scikit-learn/stable/modules/multiclass.html