

Wenn über künstliche Intelligenz gesprochen wird, werden die Begriffe KI, bzw. das englische Pendant AI, sehr oft synonym verwendet, zusammen mit Schlagworten wie
Deep Learning (DL) oder Machine Learning (ML). Es gilt jedoch diese Begriffe voneinander zu differenzieren, bzw. diese zueinander in Kontext zu setzen, um zu verstehen in welchem Teilbereich sich diese Arbeit bewegt.
Künstliche Intelligenz
Als künstliche Intelligenz (KI), bzw. Artificial Intelligence (AI), werden alle Computerprogramme bezeichnet, welche das Ziel haben menschliche Intelligenz zu simulieren. Dabei sollen die Programme möglichst autonom ihre Umwelt wahrnehmen, die Information prozessieren und daraus Entscheidungen abstrahieren, Handlungen setzen, die Resultate evaluieren und daraus lernen, um sich selbst und die angewendeten Algorithmen selbständig zu verbessern. [1]
Schwache KI
Eine schwache KI (auch Artificial Narrow Intelligence) ist für eine bestimmte Aufgabe konzipiert und bewegt sich mit ihren Fähigkeiten in genau abgegrenzten Dimensionen. Klassifizierungsalgorithmen zum Beispiel, sind als schwache KI zu klassifizieren, da sie gänzlich ungeeignet für andere Tasks sind, wie zum Beispiel ein Auto zu steuern oder Schach zu spielen. Alle derzeit vorhandenen KI-Anwendungen sind diesem Bereich zuzuordnen.
Starke KI
Eine starke KI (auch Artificial General Intelligence) hingegen sprengt die Grenzen der
schwachen KI und kann generalisiertes Wissen akquirieren und dieses auf eine Vielzahl
von Problemen anwenden. Es kann für die Zukunft geplant werden, ein Lösungsweg gesucht werden auch außerhalb der Daten, die bereits erlernt wurden und es können
Entscheidung aufgrund von „Hausverstand“ getroffen werden, wenn die Programmierung versagt. Ebenfalls ist ein definiertes Kriterium der starken, bzw. generellen KI das der Self-Awareness, also Bewusstseinsbildung der KI in Bezug auf sich selbst. Hier ist zu bemerken, dass es zum jetzigen Zeitpunkt dieser Arbeit noch keine starke KI gibt und die beschriebenen Merkmale diskutiert werden, jedoch laufen Forschung zu Thema betrieben wird.
Künstliche Intelligenz kann also als Oberbegriff mehr oder weniger autonom lernender
Programme und Maschinen verstanden werden.
Machine Learning
Machine Learning (ML) ist ein Unterbereich von KI, welcher sich damit beschäftigt, automatisiert, verschiedene Muster in Daten zu erkennen, bzw. auch Zusammenhänge
in Daten aufzuzeigen und sich dabei selbst laufend zu verbessern, meistens ohne, dass ein menschlicher Eingriff dazu nötig ist. Die Algorithmen verbessern sich durch ständige
Evaluierung der historischen Daten, dabei kann unterschieden werden zwischen „unüberwachtem“ und „überwachtem“, sowie „verstärktem“ Lernen.
Beim unüberwachten Lernen (Unsupervised Learning) wird dem Programm freie Hand gelassen, um Muster und Zusammenhänge zu erkennen. Zum Beispiel kommt dies zur Anwendung bei Clustering Algorithmen. Diese evaluieren zum Beispiel den Text von Support Tickets und Clustern die Ausgaben in Häufigkeiten vorkommender Stichworte.
Sie können noch unbekannte Kategorien aufzeigen, oder auch Zusammenhänge zwischen verschiedenen Kategorien visualisieren, welche noch nicht evident waren.
Es gibt auch das überwachte Lernen (Supervised Learning), wenn es darum geht die Modelle an den historischen Support Ticket Daten zu trainieren. Hierbei wird dem Algorithmus richtige und falsche Klassifizierung beigebracht, via Input/Output Daten-Pärchen, welche als Beispiele falscher und richtiger Klassifizierungen und Priorisierungen fungieren.
Verstärktes Lernen (Reinforcement Learning) ebenfalls zu erwähnen, es benötigt nicht die bereits vorher klassifizierten Daten-Pärchen, sondern kann als „Trial und Error Lernen“ verstanden werden, wo in einer Umgebung, bzw. mit einer gewissen Fragestellung das Programm entscheidet, welche die beste Lösung für die gegebene Situation ist.
Einer der größten Herausforderungen beim ML ist die vorher nötige Aufbereitung der
Daten, dem „Preprocessing“ und der „Feature Extraktion“, um diese in eine durch ML- Methoden verwendbare Form zu bringen.
Deep Learning
Der dritte Begriff, den es zu unterscheiden gibt, ist jener des Deep Learning. DL kann wiederrum als Unterbereich des ML betrachtet werden. Deep Learning funktioniert mittels „künstlicher neuronaler Netze“, es wird also versucht maschinell die Neuronenstruktur im Gehirn abzubilden. Sehr vereinfacht besagt das Konzept, dass Eingaben durch die Schichten eines neuronalen Netztes geschickt werden, wobei das Programm lernt die Eingaben zu klassifizieren und Outputs vorauszusagen. [2]
Steinwendner und Schwaiger definierten in Ihrem Buch „Neuronale Netze programmieren mit Python“ noch weitergehend die Einteilungen und Unterschiede zwischen KI, ML und DL. [16] Dr. Steinwendner reiht Deep Learning ein als „datenbasierte KI“, wobei keine vorgefestigten Grundregeln generiert werden (wie bei regelbasierter KI), sondern dem Algorithmus erlaubt wird eigene Regeln zu finden, jeweils basierend auf den zur Verfügung stehenden Grund- bzw. Trainingsdaten. Auf dem Gebiet des DL schreitet die Forschung schnell voran, auch im Hinblick auf die immer schneller werdende Rechenleistung und die steigende Effizienz im Hinblick auf Speicher. Der Vorteil liegt hier darin, dass sowohl unstrukturierte als auch strukturierte Daten verarbeitet werden könne, ohne dass extensive Feature Extraktion durchgeführt werden muss, jedoch geht dies zu Lasten der Ressourcenschonung. Verglichen mit ML-Methoden benötigen DL-Methoden sehr eistungsstarke Rechner, welche mit High-End GPUs ausgestattet werden müssen.
Abbildung 1 zeigt noch einmal die Zusammenhänge zwischen KI und Machine Learning
als Teilgebiet der KI, sowie dem Deep Learning als Teilgebiet des ML. Die grün markierten Bereiche sind Technologien, welche im Zuge meiner Bachelorarbeit damals behandelt wurden. Da die Abbildung aus dieser Arbeit stammt, sind die Bereiche markiert, die weißen Kategorien geben weitere Beispiele von Anwendungen aus den Bereichen.
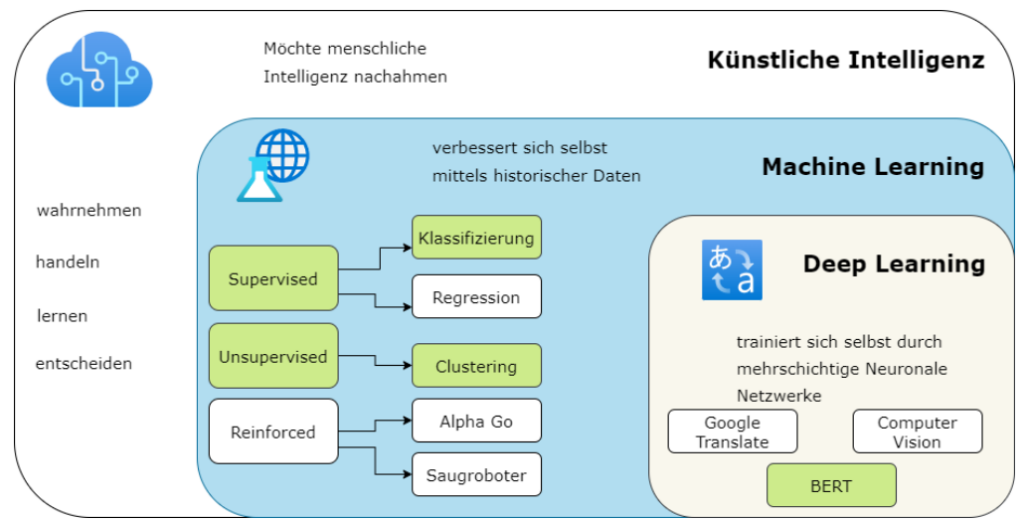
Abbildung1: Einordnung von KI, ML, DL im Bezug zueinander, frei nach Steinwendner und Schwaiger 2020, abb.1.2 [3]
Spezialfall Natural Language Processing
NLP bezeichnet Methoden mit dem Ziel Informationen aus der menschlichen Sprache
und aus geschriebenem Text zu extrahieren, zu verstehen und zu bearbeiten. Dabei sind
einige vorhergehende Schritte nötig, um einen natürlichsprachlichen Text in für ein ML-Modell verständliche Information umzuwandeln. Diese Schritte fallen in den Bereich des
Feature Engineerings und des Preprocessings, wo zum Beispiel komplexe Texte in Sätze, dann Wörter heruntergebrochen werden, die Dimensionalität des Textes reduziert wird, Stoppwörter identifiziert werde, um schlussendlich den Worten Vektorwerte zuweisen zu können mit denen das ML-Modell arbeiten kann. [4]
Deep Learning hat hier den Vorteil, dass es anders als Machine Learning mit weniger
intensivem Feature Engineering auskommt.
Bibliographie
Text dieses Artikels ist ein angepasster Auszug aus “B.Schön, Komparative Analyse von Machine-Learning Methoden zur Klassifizierung und Priorisierung von Support Tickets der Firma Springtime Technologies GmbH, Feb. 2024, Bachelorarbeit”
Originalreferenzzahlen Arbeit: [14], [15], [16],[17]
Artikelreferenzen
[1] A. M, „Artificial Intelligence vs Machine Learning vs Data Science“, Medium. Zugegriffen: 24. November 2022.
[Online]. Verfügbar unter: https://towardsdatascience.com/artificial-intelligence-vs-machine-learning-vs-datascience-2d5b57cb025b
[2] M. Przybyla, „Machine Learning vs Deep Learning“, Medium. Zugegriffen: 24. November 2022. [Online]. Verfügbar
unter: https://towardsdatascience.com/machine-learning-vs-deep-learning-6b206bb5504
[3] J. Steinwendner und R. Schwaiger, Neuronale Netze programmieren mit Python: Der Einstieg in die Künstliche
Intelligenz. Mit KI-Lernumgebung, Python-Crashkurs, Keras und TensorFlow 2. Rheinwerk Verlag GmbH, 2020
[4] A. Geitgey, „Natural Language Processing is Fun!“, Medium. Zugegriffen: 24. November 2022. [Online]. Verfügbar
unter: https://medium.com/@ageitgey/natural-language-processing-is-fun-9a0bff37854e